
K-최근접 이웃(K-Nearest Neighbor, K-NN) 알고리즘은 가장 직관적이면서 단순하지만 강력한 분류 또는 회귀모델입니다. 비슷한특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정하에 사용합니다.
KNN 알고리즘은 훈련 단계에서 학습을 하지 않고 테스트나 검증 단계에서 테스트 데이터의 관측값과 가장 가까운 k개의 훈련 데이터 관측값을 비교하는 방식으로 동작을 합니다. 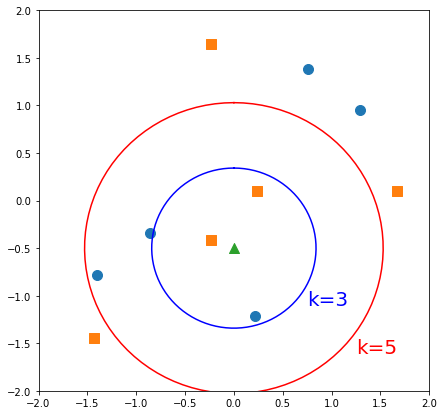
예를 들어 위에 그래프에서 주황색 사각형과 파란색 원형이 훈련 데이터 관측값이고, 녹색 삼각형이 테스트 데이터 관측값이라고 가정합시다. k=3인 경우, 녹색 삼각형에서 가장 가까운 3개의 훈련데이터를 비교합니다. 주황색 사각형의 수가 더 많으므로 테스트 데이터는 주황색 사각형으로 분류됩니다. 반면 k=5인 경우, 파란색 원형의 수가 더 많으므로 테스트 데이터는 파란색 원형으로 분류됩니다.
KNN 알고리즘은 학습을 하지 않기때문에 게으른 학습이라고 부릅니다. 거리는 유클리드 공간의 점과 점 사이의 직선거리 즉, L2 노름을 사용합니다. 거리에 의존하는 모델이므로 특징의 개수가 증가하면 성능이 크게 저하될 수 있습니다.
거리를 측정할때는 특징을 표준화(Normalization)하여 측정해야합니다. 예를 들어 x축 특징은 편차가 1000, y축 특징은 편차가 1이라고 할때 표준화 하지 않을 경우 거리에 x축의 영향력이 커져버립니다. 즉, 테스트 데이터가 (1, 1)이라면 y축 특징에 의해 분류가 되어야하지만 x축의 영향력이 크기때문에 분류가 일어나지 않습니다. 그렇기때문에 특징을 표준화하여 기준을 동일하게 해주어야 하는데 이것을 스케일링(scaling)이라고 합니다. 보통 표준편차를 1로 하는 z-score를 많이 사용합니다.
파이썬 연습
UCI Machine Learning Repository에서 wisconsin 유방암 데이터를 사용하여 knn 분류모델을 만들어보겠습니다.
데이터 주소는 다음과 같습니다. https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data
데이터에 대한 정보는 다음 파일을 참고하세요. https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.names
데이터 정보에 의하면 해당 데이터에는 하나의 특징에서 16개의 인스턴스가 누락되어 "?"로 표시되어 있다고 합니다. 데이터에 컬럼 이름을 붙이고 info 함수를 통해 데이터프레임 정보를 확인하겠습니다. 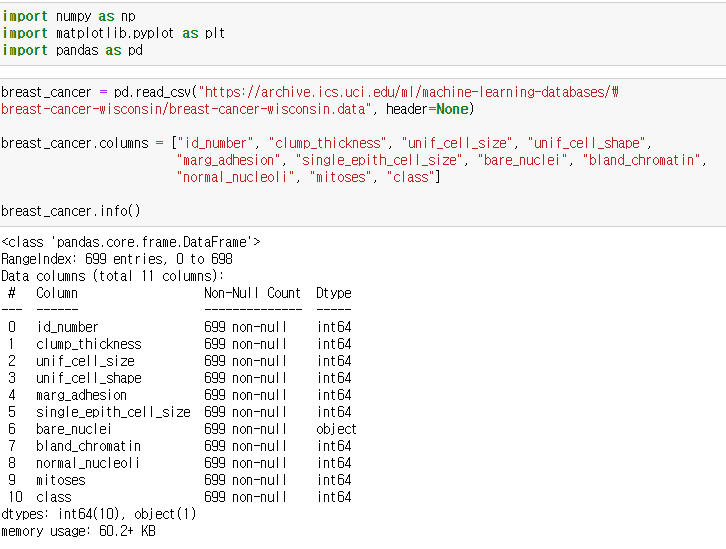
bare_nuclei 특징의 데이터타입이 object로 되어있습니다. 즉, 해당 특징의 데이터에 문자열 "?" 가 섞여있다는 뜻입니다. 누락된 데이터를 최빈값으로 입력하도록 하겠습니다.

특징행렬은 id_number, class를 제외한 모든 특징을 사용하며, 대상벡터는 class로 합니다.

사이킷런 모듈의 train_test_split 함수를 통해 훈련 데이터와 테스트 데이터로 나눕니다.

특징을 표준화합니다. 사이킷런 모듈의 StandardScaler 함수를 사용하면 됩니다.
이때 훈련 데이터는 스케일러의 fit_transform 메소드로 훈련후 변환하고, 테스트데이터는 훈련된 스케일러의 transform 메소드를 통해 변환만 합니다. 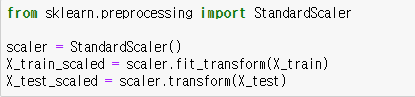
사이킷런 모듈의 KNeighborsClassifier 함수를 통해 KNN 분류모델을 생성할 수 있습니다. 하이퍼 파라미터 n_neighbors에 k값을 설정합니다. 그리드 서치를 통해 1부터 5까지 설정하겠습니다. 그리드서치 모델을 훈련하여 best_estimator_ 속성을 통해 최적의 모델을 선택합니다. 해당 모델에 테스트 데이터를 넣어 예측값을 저장합니다.
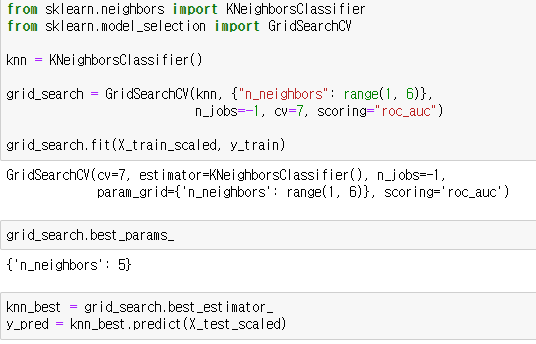
AUC 점수를 통해 모델을 평가해보세요. 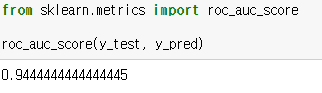
|  스팟
스팟