
회귀모델에서는 MSE의 최소값을 통해 최적의 모델을 찾았습니다. 그런데 다중회귀모델의 경우 복잡도가 높기때문에 과대적합(overfitting) 되는 경향이 있습니다. 이를 해결하기 위해 모델 자체적으로 규제를 주어 복잡도를 감소시키는 방법이 있는데 대표적으로 라쏘(LASSO)와 릿지(Ridge)가 있습니다.
1) 노름(Norm)
라쏘와 릿지를 알기전에 우선 노름이 무엇인지에 대해 설명하겠습니다. 노름이란 벡터의 크기를 측정하는 방법입니다. 벡터의 크기는 다음과 같은 방정식을 통해 나타낼 수 있습니다.
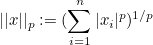
p는 차수, n은 차원을 나타냅니다. 차수가 1인 노름을 L1 노름, 차수가 2인 노름을 L2 노름이라고 합니다.
L1 노름은 맨해튼 노름(Manhattan norm) 또는 택시 노름(Taxicab norm)이라고도 불립니다.
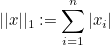
아래 그림처럼 A에서 B까지의 거리는 맨해튼 거리에서 택시를 타고 이동한 거리와 같습니다. 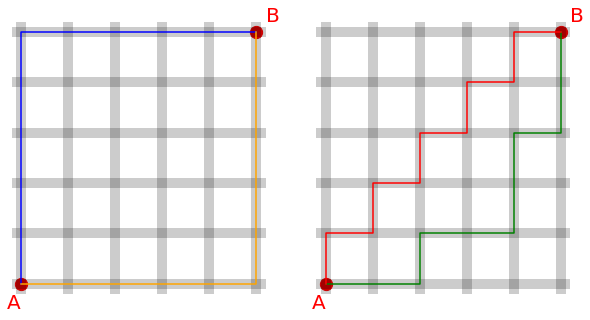
즉, A(0,0)에서 B(5,5)까지의 L1 노름은 |5-0| + |5-0| = 10 입니다.
L2 노름은 유클리드 노름(Euclidean norm)이라고도 불립니다.
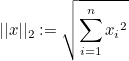
아래 그림처럼 두 점 사이의 최소거리와 같습니다. 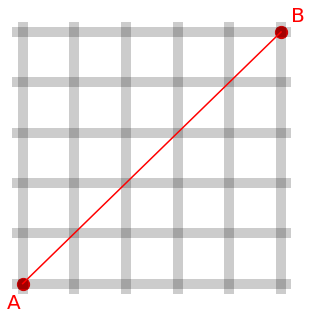
즉, A(0,0)에서 B(5,5)까지의 L2 노름은 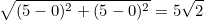 입니다. 입니다.
L1 노름과 L2 노름을 유클리드 좌표상에 나타내면 다음과 같습니다. 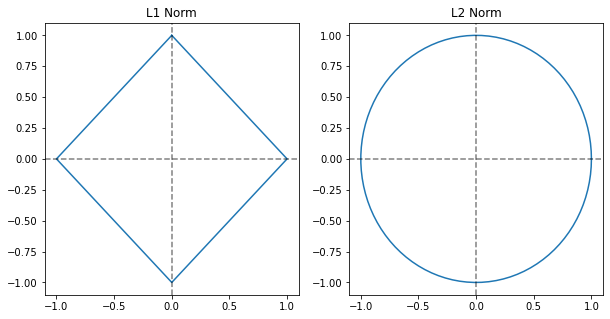
2) 정규화(Regularization)
정규화는 노름을 통해 규제를 두어 모델의 복잡도를 감소시키는 방법입니다. 즉, L1 규제를 통한 정규화를 라쏘(least absolute shrinkage and selection operator, LASSO), L2 규제를 통한 정규화를 릿지(Ridge)라고 합니다.
정규화 모델에서 비용함수는 다음과 같습니다.
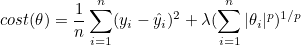
즉, MSE와 규제(penalty)로 구성됩니다. λ는 하이퍼 파라미터인 학습률(learning rate)입니다. 학습률이 커질수록 규제에 의한 영향력이 커지므로 MSE는 상대적으로 감소합니다. 즉, 예측률이 증가합니다.
규제에 의하여 파라미터는 다음과 같이 제한됩니다.
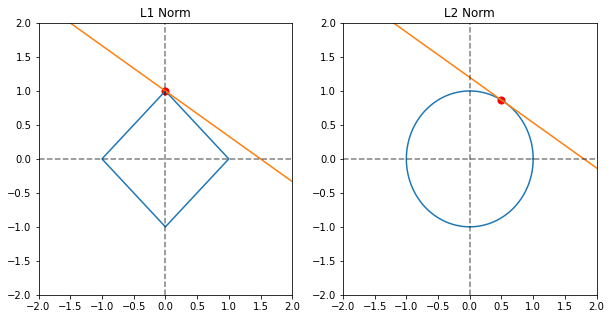
파라미터가 2개인 경우의 규제모델입니다. 파란색 도형은 규제를 나타내며, 주황색 선은 파라미터 θ0와 θ1의 관계를 나타냅니다. 규제항이 0에 수렴할때 L1 정규화의 경우 주황색 선의 절편인 θ1은 0이 될 수 있지만 L2 정규화의 경우 0에 가까워져도 완전히 0은 되지 않습니다. 또한 L1 노름의 경우 미분이 불가능하므로 경사하강법을 통해 학습하는 모델에는 적합하지 않을 수 있습니다.
즉, 특성의 일부분이 중요하다면 L1 정규화를 사용하는 라쏘 모델이, 특성의 중요도가 전체적으로 비슷하거나 경사하강법을 통해 학습하는 모델의 경우 L2 정규화를 사용하는 릿지모델이 최적화된 모델을 생성할 것입니다.
3) 파이썬 연습
사이킷런 모듈의 Lasso 함수와 Ridge 함수를 통해 모델을 생성할 수 있습니다.
데이터는 레드와인과 화이트와인 데이터를 통합하여 사용하겠습니다.
우선 라쏘모델을 다음과 같이 학습률을 달리하여 생성해봅시다. 
학습률이 커질수록 파라미터(계수)값이 감소합니다. 또한 일부 특성의 파라미터만 선택되고 나머지는 0이 되어 자체적으로 특성선택이 되었음을 확인할 수 있습니다.

이번에는 릿지 모델을 학습률을 달리하여 생성해봅시다. 
라쏘와 마찬가지로 학습률이 커질수록 파라미터 값이 감소합니다. 하지만 라쏘와 달리 모든 파라미터 값이 작은 값으로도 존재합니다. 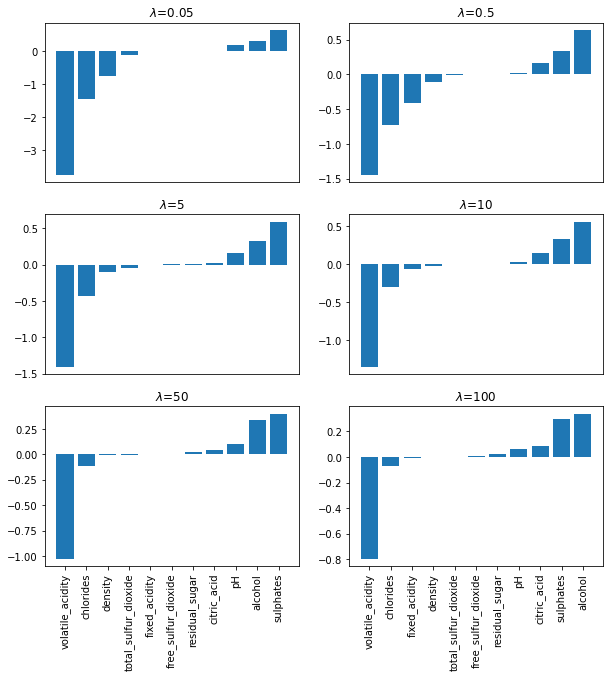
|  스팟
스팟