
1. JPA(Java Persistence API)란?
JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준으로, ORM 프레임워크를 쉽게 사용하기 위한 인터페이스의 모음입니다.
데이터베이스 연동에 사용되는 기술은 JDBC에서부터 Spring DAO, MyBatis, Hibernate 등 다양합니다. 이 중에서 Hibernate같은 ORM 프레임워크는 SQL까지 프레임워크에서 제공하여 개발자들이 처리해야 할 업무가 상당히 감소했습니다.
이전에는 데이터베이스에 연동하기 위해 SQL Query를 직접 작성하여 영속 데이터를 가져왔습니다. 이 경우 여러 문제점이 있는데 데이터베이스의 테이블이 변경되더라도 SQL Query는 String 형식으로 되어있어서 컴파일 에러가 나오지 않습니다. 또한 Query문을 잘못 작성하더라도 컴파일시 확인할 수 없어서 런타임에서 에러를 발생시킵니다. 이러한 이유로 개발자들은 순수 객체지향 프로그래밍에 집중하지 못하고 Query문 작성에 많은 비용을 지불해야만 했습니다.
하지만 Hibernate의 등장으로 이런 문제들이 해소되어 이후 많은 ORM 프레임워크가 등장했으며, 이런 ORM을 보다 쉽게 사용할 수 있도록 표준화 시킨 것이 JPA(Java Persistence API) 입니다.
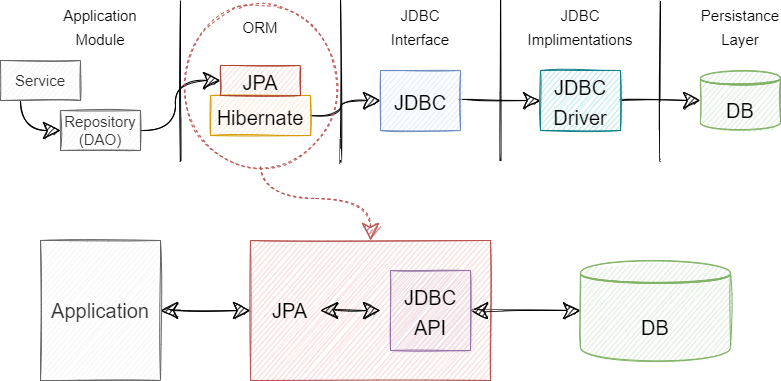
JPA는 애플리케이션과 JDBC 사이에서 동작합니다. 기존 마이바티스 같은 프레임워크는 SQL을 개발자가 직접 XML 파일에 등록하여 사용했지만, JPA를 사용하면 JPA 내부에서 JDBC API를 통해 SQL을 호출하여 DB와 통신하게 됩니다. 즉, 개발자가 직접 JDBC API를 사용하지 않습니다.
JPA의 장점은 CRUD SQL을 작성할 필요가 없고 조회된 결과를 객체로 매핑하는 작업을 자동으로 처리하기 때문에 데이터 저장 계층에서 작성해야할 코드가 대폭적으로 줄어듭니다. 또한 SQL이 아닌 객체 중심으로 개발하여 생산성과 유지보수가 좋아집니다.
그러나 배우기가 어렵고 잘 이해하지 않으면 데이터 손실이 있을 수 있으며, 복잡한 작업에 대해서는 성능상 문제가 있을 수 있습니다.
1) 객체-관계 매핑(Object Relational Mapping, ORM)
ORM이란 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해주는 기술을 말합니다.
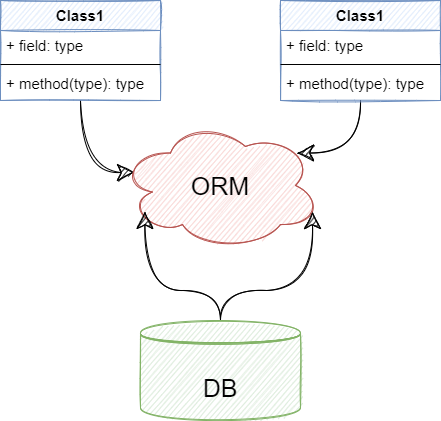
기본적으로 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용하기 때문에 객체 모델과 관계형 모델 간에 불일치가 존재합니다. ORM은 객체 간의 관계를 바탕으로 SQL을 자동으로 생성함으로써 이런 패러다임의 불일치 문제를 해결해줍니다.
2) Hibernate

JPA가 제공하는 인터페이스를 이용하여 데이터베이스를 처리하면 실제로는 Hibernate 같은 구현체(Implimentations)가 동작합니다. 그렇기 때문에 Hibernate를 통해 개발하더라도 실제 서비스에서는 다른 ORM 기술인 EclipseLink로 변경하더라도 동일한 서비스를 제공할 수 있습니다.
2. 5 레이어 아키텍처(5 Layer Architecture)
스프링 프레임워크는 MVC 패턴을 좀더 세분화 하여 5 레이어 아키텍처(5 Layer Architecture)로 나타낼 수 있습니다.
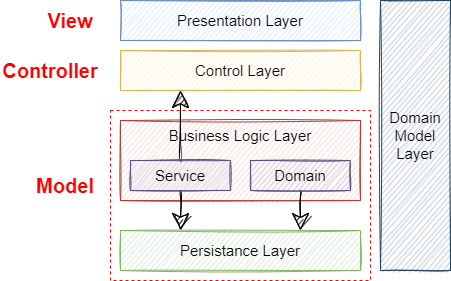
모델(Model)은 비즈니스 로직 계층(Business Logic Layer)과 영구 계층(Persistence Layer), 도메인 모델 계층(Domain Model Layer)에 해당합니다.
여기에서 비즈니스 로직 계층(Business Logic Layer)은 주로 상태 변화를 처리하는 역할을 하며, 컨트롤러와 JPA를 연결해주는 서비스(Service)와 객체를 연관 테이블과 매핑해주는 도메인(Domain)으로 나눌 수 있습니다.
기존에는 비즈니스 로직과 ORM 기능을 모두 이 계층에서 수행했지만 이를 분리하여 비즈니스 로직은 서비스에서, ORM 기능은 도메인에서 수행합니다.
비즈니스 로직과 관련된 객체들은 다음과 같습니다.
1) DAO(Data Access Object)
DAO(Data Access Object)는 DB에 접근하여 CRUD를 할 수 있는 객체입니다. 서비스와 DB를 연결해주며, 구현체에 CRUD 기능을 구현하고 이를 의존성 주입(DI)해주는 방식으로 사용됩니다. 스프링에서는 Repository가 DAO 역할을 하는데, DB 접근 방식에 약간의 차이가 있다고 합니다.
2) DTO(Data Transfer Object)
DTO(Data Transfer Object)는 계층 간 데이터 교환을 하기 위해 사용하는 객체입니다. 로직을 가지지 않는 순수한 데이터 객체로서, getter나 setter 정도의 메소드를 가질 수 있습니다.

이와 비슷한 VO(value Object) 객체는 오직 읽기만 가능한 read-Only 특징을 가지며, getter 메소드만 가지고 있습니다.
3) Domain(=Entity)
도메인은 DB 테이블과 매핑되는 객체입니다. 변경사항이 생기면 여러 다른 클래스에 영향을 주기때문에 변경사항이 많은 DTO와 분리하여 사용됩니다.
JPA에서 도메인의 생성에는 @Entity, @Column, @Id 등과 같은 어노테이션(annotation)이 사용됩니다.
import lombok.*;
import javax.persistence.*; import java.util.Date;
@Getter @Setter @ToString @Entity public class Board { @Id @GeneratedValue private Long seq; private String title; private String writer; private String content; @Temporal(TemporalType.DATE) private Date createDate; private Long cnt; } |
3. 엔티티(Entity)
엔티티(Entity)는 데이터베이스의 테이블과 연결하기 위한 개념적인 객체를 말하며, 여러 인스턴스의 집합으로 구성됩니다. 예를 들어 "동물" 이라는 엔티티가 있다면, "강아지", "고양이", "개구리", "금붕어" 등은 동물 엔티티를 구성하는 인스턴스가 됩니다.
인스턴스는 속성(Attribute)에 의하여 구분될 수 있습니다. 예를 들어 동물이라는 엔티티는 "종(Species)"이라는 속성을 가지며, 종(Species) 속성은 강아지와 고양이 인스턴스를 포유류로, 개구리를 양서류로, 금붕어를 어류로 구분할 수 있습니다.
하나의 속성이 가지는 값의 범위를 도메인(Domain)이라고 합니다. 예를 들어 강아지는 수많은 개체로 이루어져 있지만 강아지라는 하나의 도메인으로 나타낼 수 있습니다.
엔티티(Entity)는 객체지향 언어에서 클래스(Class)와 매핑될 수 있으며, 속성(Attribute)은 클래스의 멤버변수(Member variable) 또는 필드(Field)와 연결할 수 있습니다. 필드는 클래스 내에서 유일하게 존재하므로 ORM에 의하여 매핑된 엔티티는 도메인과 같은 의미를 가집니다.
JPA에서 엔티티의 선언은 @Entity 어노테이션을 사용합니다.
@Entity
public class Species { private Long seq; private String name; } |
객체(Object)와 테이블(Table)을 매핑하기 위한 Id 속성이 필요하므로, 하나의 엔티티는 적어도 2개의 속성을 가지게 됩니다.
위에서 Species 엔티티는 Id 속성인 seq와, 엔티티의 이름을 나타내는 name 속성으로 구성됩니다. seq는 테이블에서 기본키(Primary Key, PK)와 매핑되므로, 해당 속성이 Id 속성이라는 것을 선언할 필요가 있습니다. JPA에서는 @Id 어노테이션으로 Id 속성을 선언할 수 있습니다.
@Entity
public class Species {
@Id private Long seq;
private String name; } |
Id 속성은 유일한 값을 가져야 하는데, @GeneratedValue 어노테이션을 붙이면 자동으로 Id를 생성해줍니다. 그러므로 기본적인 엔티티는 다음과 같은 형태가 됩니다.
@Entity
public class Species {
@Id @GeneratedValue private Long seq;
private String name; } |
엔티티 클래스의 작성은 다음 글에서 자세하게 다뤄보도록 하겠습니다.
4. 영속성 컨텍스트(Persistence Context)
영속성 컨텍스트는 데이터가 영속성을 부여받는 환경을 말합니다. 영속성을 부여받았다고 해서 완전히 사라지지 않는 것은 의미하지는 않습니다. 영속성 컨텍스트에 저장된 데이터는 프로그램이 종료되면 컨텍스트와 함께 메모리에서 사라져 버립니다.
영속성 컨텍스트는 EntityManager가 가지고 있습니다. EntityManager는 영속성 컨텍스트를 통해 CRUD를 수행할 수 있습니다.
영속성 컨텍스트는 크게 1차 캐시 저장소와 SQL 저장소로 구분됩니다.

1차 캐시 저장소에는 Entity 정보를 저장합니다. 이 상태를 영속 상태라고 합니다.
SQL 저장소에는 SQL Query를 저장합니다. 저장된 쿼리는 EntityManager의 flush() 메소드에 의하여 DB에 반영됩니다.
5. Entity 생명주기(Lifecycle)
Entity는 EntityManager가 제공하는 메소드를 통해 관리되며, 다음과 같이 4가지 상태로 존재합니다.
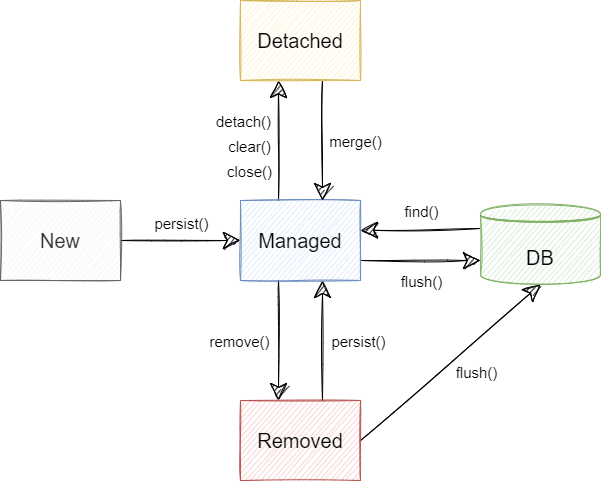
1) 비영속 상태(New)
비영속 상태는 Entity 객체만 생성하고 아직 Entity를 영속성 컨텍스트에 저장하지 않은 상태입니다.

2) 영속 상태(Managed)
영속 상태는 Entity 객체가 영속성 컨텍스트에 저장된 상태입니다. Id를 키(key)로 하여 Entity가 1차 캐시 저장소에 저장됨과 동시에 SQL 저장소에는 INSERT Query가 저장됩니다.
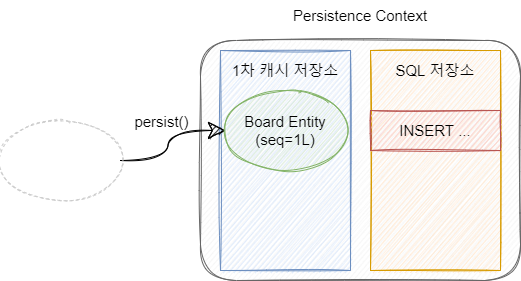
이 상태에서는 Entity를 영속성 컨텍스트가 관리하는 상태이므로 객체의 상태변경을 자동으로 감지합니다. 이것을 Dirty Checking이라고 합니다.
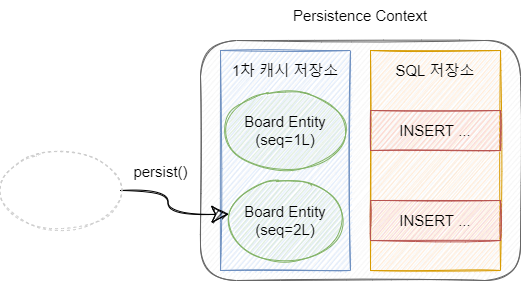
영속 상태가 되기 위해서는 EntityManager의 persist() 메소드를 사용합니다. persist() 메소드를 통해 Entity가 영속화 되어도 flush() 메소드가 호출되기 전까지는 DB에 쿼리가 전달되지 않고 SQL 저장소에 쌓입니다.
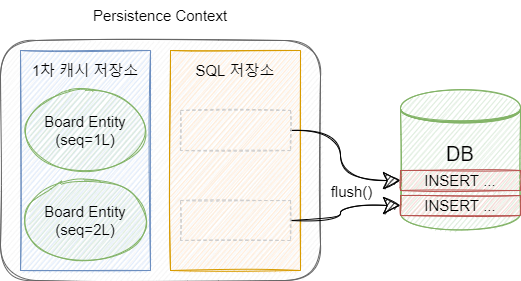
ntityManager의 flush() 메소드가 호출되면 SQL 저장소의 모든 쿼리가 DB에 반영됩니다. flush를 하더라도 Entity는 영속성 컨텍스트에 계속 저장되어 있습니다. 단지 영속성 컨텍스트와 DB를 동기화(Synchronize)할 뿐입니다.
persist() 메소드 뿐만 아니라 EntityManager의 find() 메소드를 통해서도 DB의 데이터를 통해 Entity 객체를 만들어 영속성 컨텍스트에 저장함으로써 영속 상태가 될 수 있습니다.
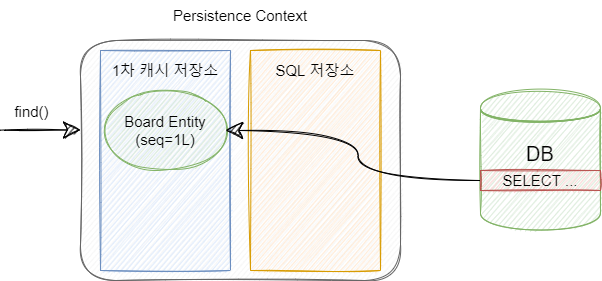
만약 같은 Entity를 조회한다면 JPA는 1차 캐시 저장소에 있는 Entity를 반환하게 되므로 성능상 큰 이점을 얻을 수 있습니다.
3) 준영속 상태(Detatched)
EntityManager의 detach() 메소드 또는 clear(), close() 메소드가 호출된 경우 Entity는 준영속 상태가 됩니다.
detach() 메소드는 특정 Entity를 준영속 상태로 전환합니다.
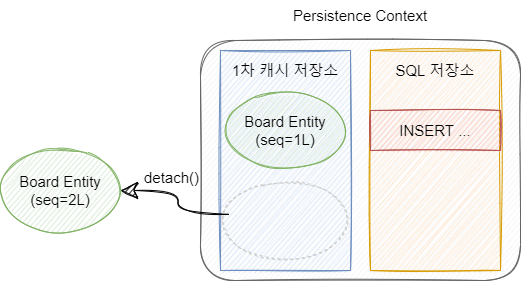
clear() 메소드는 영속성 컨텍스트 안의 모든 Entity를 준영속 상태로 만듭니다.

close() 메소드는 EntityManager를 닫아 영속성 컨텍스트를 종료하고 영속성 컨텍스트 안의 모든 Entity를 준영속 상태로 만듭니다.

준영속 상태가 된 Entity는 EntityManager의 관리를 벗어나기 때문에 Dirty Checking을 하지 않습니다. 하지만 완전히 메모리에서 사라진 것은 아니기 때문에 EntityManager의 merge() 메소드를 통해 다시 영속상태로 전환될 수 있습니다.
여기에서 중요한 것은 board 객체 자체가 다시 영속상태가 되는 것이 아니라는 것입니다. merge라는 말처럼 새로운 Entity에 board 객체의 모든 필드를 합병하고 새로운 객체를 1차 캐시 저장소에 저장합니다. 즉, merge는 UPDATE 기능을 수행합니다.
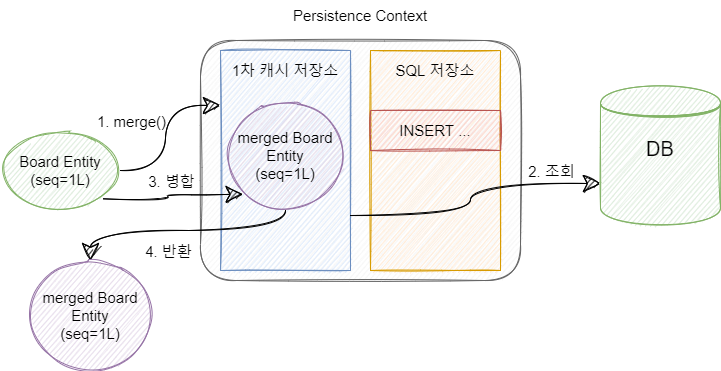
EntityManager로부터 merge 메소드가 호출되면 우선 DB에서 Id 필드와 같은 동일한 기본키를 조회합니다. 동일한 기본키가 없다면 새로운 Entity에 board Entity를 합병하고 합병된 Entity를 반환합니다. 이때 SQL 저장소에는 INSERT Query가 저장됩니다.
동일한 기본키가 있다면 해당 Entity를 영속화하여 board Entity를 합병합니다. 이때 SQL 저장소에는 UPDATE Query가 저장됩니다.
사실 1차 캐시 저장소에는 entity 자체가 저장되는 것이 아니라 Entity의 Reference와 Snapsot을 저장하고 있습니다.
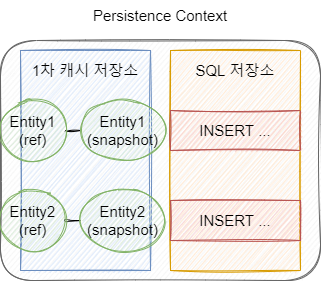
flush가 호출되고 실행되기 전에 EntityManager는 실제 Entity와 Snapshot을 비교하여 변경을 감지할 수 있습니다. 내용이 변경되었다면 UPDATE Query를 생성하여 DB를 update 할 수 있습니다.
주의할 것은 Entity의 모든 필드가 교체되므로 값이 null이 될 가능성이 있다는 것을 숙지해야합니다.
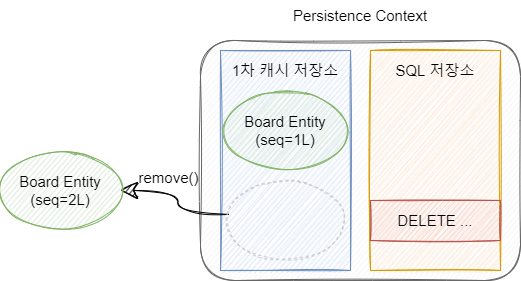
4) 삭제 상태(Removed)
EntityManger의 remove() 메소드로 Entity를 삭제하면 해당 Entity는 영속성 컨텍스트에서 제외되고 DELETE Query가 SQL 저장소에 저장됩니다.
|  스팟
스팟