
지난번 글에 이어서 사이킷런을 통해 모델을 만들어보도록 하겠습니다.
우선 캐글에서 CTR 예측 훈련데이터를 주피터 노트북 루트폴더에 다운로드합니다. https://www.kaggle.com/competitions/avazu-ctr-prediction/data?select=train.gz
캐글 회원가입이 필요합니다. 구글아이디로 가입하셔서 휴대폰 인증후 자료를 다운받을 수 있습니다. 100만건 이상 CTR 데이터가 존재하여 약 1기가 정도의 큰 데이터입니다. 여기서 10만건을 훈련데이터로, 그다음 10만건을 테스트 데이터로 사용하도록 하겠습니다.
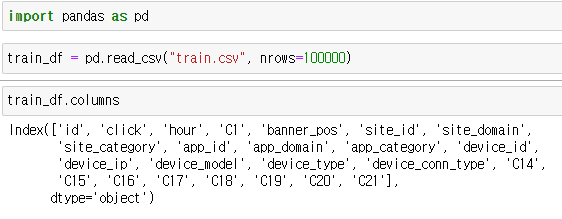
컬럼을 확인하면 여러 특징이 존재하는데 여기서 의미없는 id, hour, device_id, dvice_ip는 제외하고, click은 대상벡터로 사용하도록 하겠습니다.
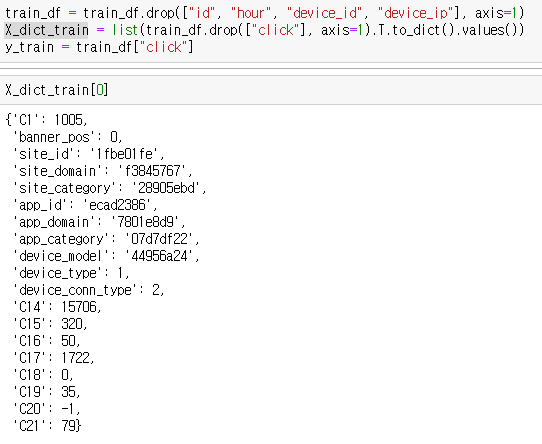
사이킷런의 트리모델은 수치를 기반으로 분류합니다. 그러므로 범주형 데이터를 수치형으로 바꿔주는 전처리 과정인 원핫 인코딩(One-Hot Encoding)을 해야합니다. 그러므로 특징행렬을 위에 그림과 같이 딕셔너리 형태로 바꿔줍니다.
원핫 인코딩은 쉽게 말해서 단어 집합의 크기를 벡터 차원으로 생각하여 해당 단어의 차원에는 1을, 나머지 차원에는 0을 할당하는 단어의 벡터 표현 방식입니다. 예를 들어 ["a", "b", "c", "d"] 라는 단어 집합이 있고 {"a": 1, "b": 2, "c": 3, "d": 4} 로 인코딩한다면 "a"는 [1, 0, 0, 0]으로 나타낼 수 있습니다. 이렇게 표현된 벡터를 원핫 벡터라고 합니다.
테스트 데이터도 동일하게 만들어주도록 합시다. 
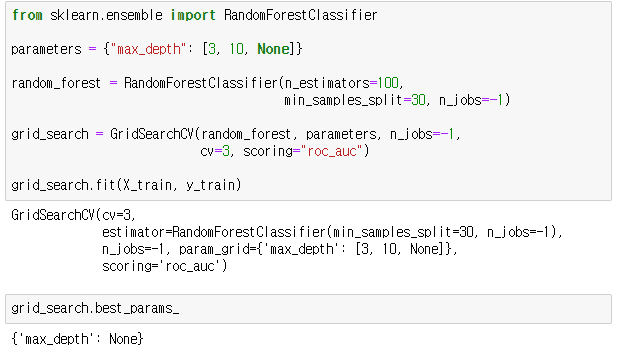
그리드 서치를 통해 최적의 결정트리 모델을 찾도록 하겠습니다.
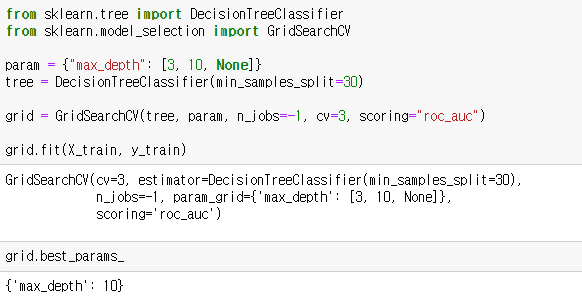
트리모델의 min_samples_split는 분기를 위한 최소한의 샘플수를 제한하는 하이퍼 파라미터입니다. 과적합을 예방하기위해 30으로 설정합니다.
그리드서치 모델에서 하이퍼 파라미터 n_jobs 는 그리드서치에 사용하는 CPU 코어 갯수를 말하며 -1은 전체 코어를 사용한다는 말입니다. 하이퍼 파라미터 scoring은 평가기준을 말합니다. 선형회귀모델에서 평가지표로 RMSE를 사용했듯이 트리모델에서는 roc_auc라는 곡선면적을 사용합니다. 아래에서 설명하도록 하겠습니다.
최적의 트리모델의 depth는 10인 것을 확인할 수 있습니다.
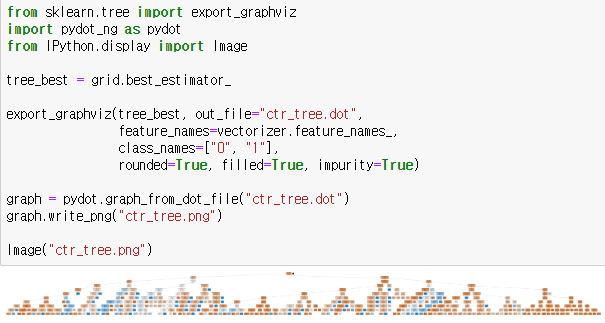
최적의 트리모델을 pydot 모듈을 통해 이미지파일로 저장하면 위의 그림과 같이 엄청난 크기의 트리를 볼 수 있습니다.
1. 혼돈행렬(Confusion Matrix)
트리모델의 성능을 평가하기 위해 혼돈행렬(confusion matrix)이라는 형태의 행렬을 사용합니다. 혼돈행렬의 모습은 다음과 같습니다.
|
양성이라고 예측 |
음성이라고 예측 |
실제 양성 |
TP(진양성) |
FN(위음성) |
실제 음성 |
FP(위양성) |
TN(진음성) |
가설검정표와 비슷해 보입니다. 귀무가설을 음성, 대립가설을 양성이라고 보면 FN은 귀무가설을 채택하여 발생한 제 2종 오류에 해당하고, FP는 귀무가설을 기각하여 바생한 제 1종 오류에 해당합니다.
- TP(True Positive)는 참이라 예측하고 실제 참인 경우입니다. ex) 코로나 양성판정을 받았는데 실제 코로나에 걸렸다.
- FP(False Positive)는 참이라 예측했지만 실제 거짓인 경우입니다. ex) 코로나 양성판정을 받았지만 실제 코로나에 걸리지 않았다.
- FN(False Negative)는 거짓이라 예측했지만 실제 참인 경우입니다. ex) 코로나 음성판정을 받았지만 실제 코로나에 걸렸다.
- TN(True Negative)는 거짓이라 예측하고 실제 거짓인 경우입니다. ex) 코로나 음성판정을 받았고 실제 코로나에 걸리지 않았다.
즉, 앞에 True, False는 예측이 맞았는지 틀렸는지 나타내고, 뒤에 Positive, Negative는 예측한 것을 나타냅니다.
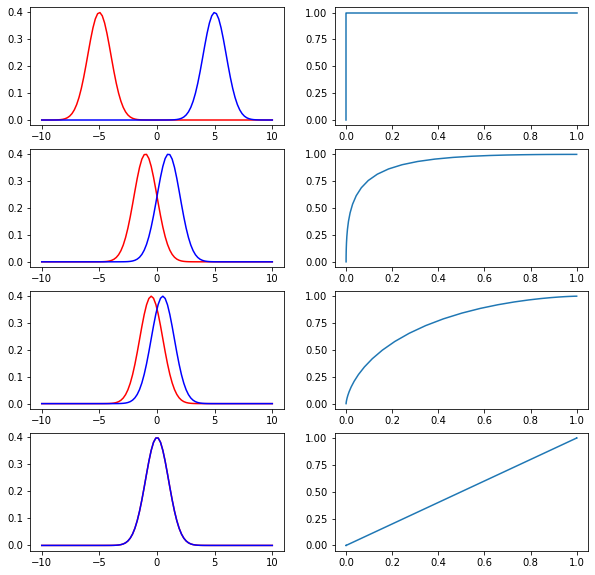
정규분포를 통해 트리모델을 나타내면 다음 그래프와 같습니다. 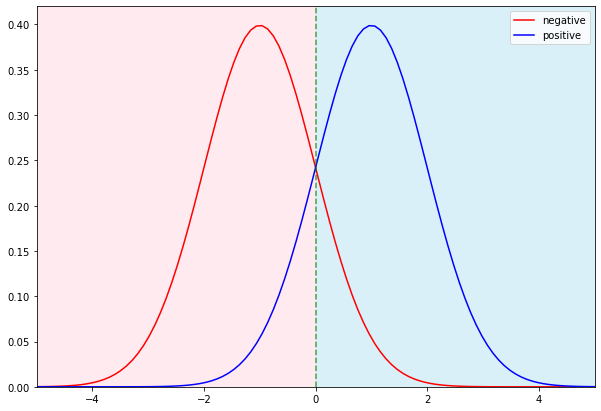
빨간색 곡선은 실제 음성인 집단이고, 파란색 곡선은 실제 양성인 집단입니다. 녹색 점선은 분기점(threshold)을 나타내며, 분기점을 기준으로 왼쪽은 음성이라고 예측, 오른쪽은 양성이라고 예측한 것입니다.
양성 집단에서 TP와 FN은 다음과 같습니다. 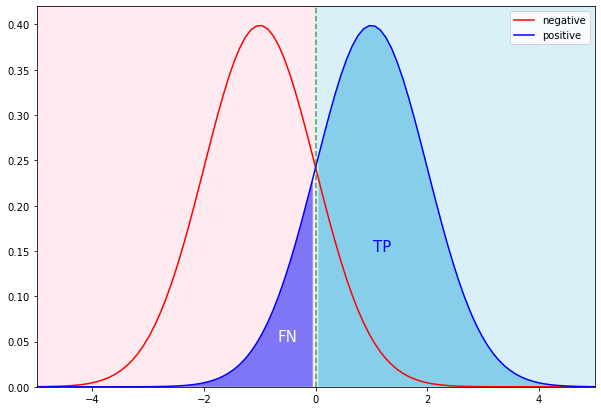
음성집단에서 TN과 FP는 다음과 같습니다. 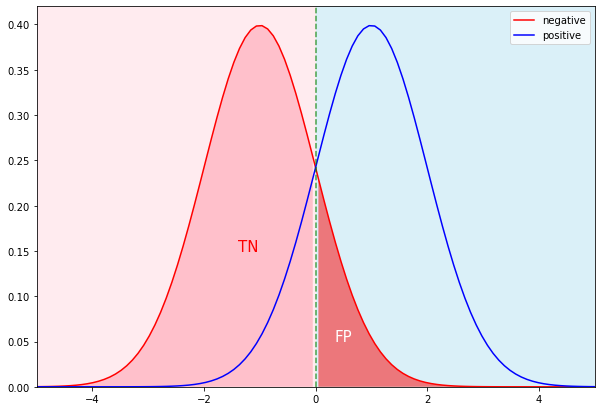
혼돈행렬을 통해 여러 평가지표를 나타낼 수 있습니다.
(1) 정확도(accuracy) : 실제와 예측이 일치하는 경우의 비율입니다. 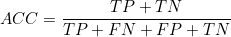
(2) 정밀도(precision) : 양성판정을 받은 사람들 중 실제 양성인 사람들의 비율입니다. 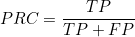
(3) 민감도(sensitivity) : 실제 양성인 사람들 중 양성이라고 판정받은 사람들의 비율입니다. 재현율(recall)이라고도 합니다. 위에 확률밀도함수에서 TP+FN은 1이므로 TP는 진양성율(TPR)을 나타냅니다. 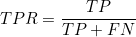
(4) 위양성율(FPR) : 실제 음성인 사람들 중 양성이라고 판정받은 사람들의 비율입니다. 위에 확률밀도 함수에서 FP + TN은 1이므로 제 1종 오류를 나타냅니다. 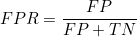
(5) 특이도(Specificity) : 실제 음성인 사람들 중 음성이라고 판정받은 사람들의 비율입니다. 1에서 위양성율을 뺀 값과 같습니다. 위에 확률밀도 함수에서 FP + TN은 1이므로 진음성율(TNR)을 나타냅니다. 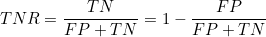
(6) F1 score : 정밀도와 재현율의 조화평균입니다. 
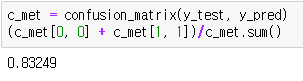
정확도는 사이킷런 모듈의 accuracy_score 함수를 통해 구할 수 있습니다.

혼돈행렬은 사이킷런 모듈의 confusion_matrix 함수를 통해 구할 수 있습니다.
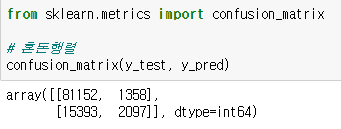
혼돈행렬을 통해 정확도를 계산해도 같은 값이 나옵니다.
마찬가지로 정밀도는 precision_score 함수, 민감도는 recall_score 함수, f1 score는 f1_score 함수를 통해 값을 구할 수 있습니다.
2. ROC(Receiver Operating Characteristics) 커브
ROC 커브는 위양성율(FPR)과 진양성율(TPR)의 관계를 나타낸 곡선입니다.
위에 정규분포로 나타낸 트리모델에서 분기점(threshord)을 왼쪽 끝에서 오른쪽 끝으로 이동시키면서 ROC 커브를 그리면 다음과 같습니다.
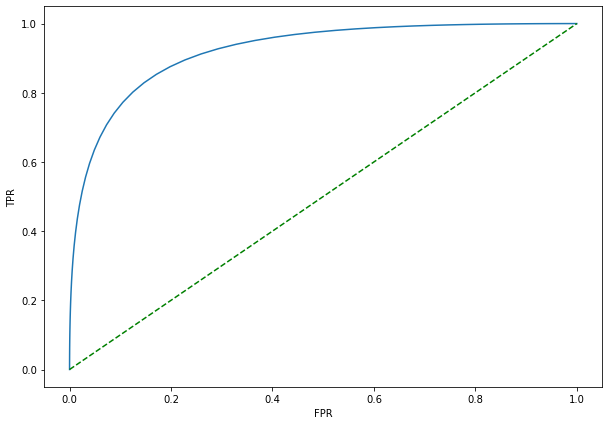
파란색 곡선이 ROC 커브입니다. 녹색 점선은 랜덤 예측(random guess)을 말하며, TPR과 FPR이 같은 경우입니다. 즉, 랜덤 예측으로부터 커브가 위를 향할수록 TPR이 FPR보다 크므로 더 좋은 분류모델이라 볼 수 있습니다.
ROC 커브의 아래 면적을 AUC(Area Under The Curve)라고 합니다. 분류모델은 AUC를 통해 성능을 평가합니다. 아까 그리드 서치 모델을 만들때 하이퍼 파라미터 scoring을 roc_auc로 설정했습니다.
트리 모델에서 predict_proba 함수를 통해 대상벡터의 확률을 구할 수 있습니다. 이 모델에서 대상벡터는 0과 1로 이루어져 있으므로 0이 나올 확률과 1이 나올 확률이 행벡터로 구성되어 있습니다. 인덱싱을 통해 1이 나올 확률만 추출해주세요.
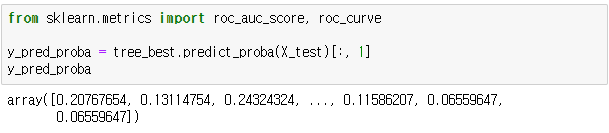
roc 커브는 roc_curve 함수, auc는 roc_auc_score 함수를 통해 구할 수 있습니다. 하이퍼 파라미터로 실제 대상벡터와 예측값의 확률 벡터를 넣어줍니다. 예측값의 확률 벡터는 위에서 추출한 y_pred_proba 입니다.

플롯을 출력하면 AUC는 0.72이고 ROC 커브는 다음과 같이 랜덤 추측선으로부터 커브가 위로 형성됨을 확인할 수 있습니다. 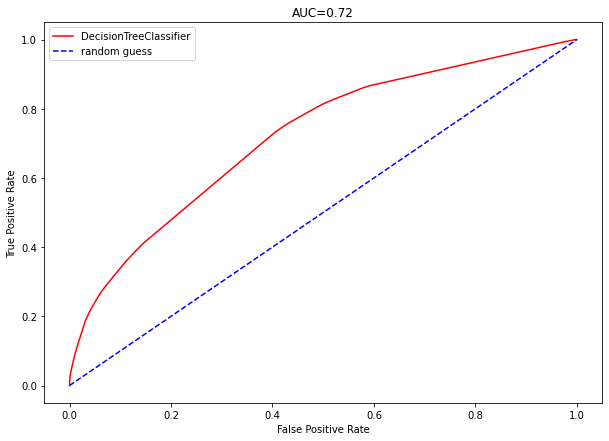
3. 앙상블 학습(Ensemble Learning)
앙상블 학습(Ensemble Learning)이란 여러개의 분류 모델을 통해 분류모델의 성능을 향상시키는 것을 말합니다. 분류모델은 그 자체가 고분산 모델이므로 과대적합이 되어 하나의 모델을 계속 학습한다면 성능이 떨어질 수 밖에 없습니다. 이때 앙상블 학습을 통해 분산을 감소시켜 모델의 성능을 향상시킬 수 있는데, 앙상블 학습에는 배깅(Bagging)과 부스팅(Boosting) 등이 있습니다.
배깅(Bagging)은 Bootstrap Aggregating의 약자로, 부트스트랩(Bootstrap)을 통해 여러 모델을 학습시켜 결과물을 취합(Aggregation)하여 모델의 성능을 향상시키는 방법입니다. 배깅을 알기위해서는 부트스트랩이 무엇이고 어떤 효과가 있는지를 알아야합니다.
부트스트랩(Bootstrap)이란 표본의 복원추출을 뜻합니다. 부트스트랩을 통해 추출된 표본집단들은 각자 모집단과 다른 평균값을 가지게 됩니다. 즉, 편향(bias)이 커집니다. 분산은 편향과 트레이드오프 관계에 있으므로 편향이 커짐에 따라 분산은 감소하게 됩니다. 표본평균의 평균은 모집단의 평균과 비슷합니다. 결과적으로 배깅을 통해 훈련된 모델은 하나의 모델을 훈련시킬 때보다 전체적으로 편향은 비슷하고 분산은 줄어든 효과를 가지게 됩니다.
부스팅(Boosting)은 가중치를 통해 분산을 감소시켜 성능을 향상시키는 방법입니다. 배깅은 각각의 모델이 서로 독립적으로 훈련되어 결과값이 취합되지만, 부스팅은 앞에 훈련된 모델에 의해 부여된 가중치가 다음 모델에 영향을 줍니다.
4. 랜덤 포레스트(Random Forest)
랜덤 포레스트는 특징을 기반으로 하는 배깅을 통한 결정트리의 앙상블입니다. 포레스트라는 단어에서 여러 트리가 모였다는 것을 알 수 있습니다. 즉, 특징을 부트스트랩을 통해 추출하여 여러 트리 모델을 만들고, 그 결과를 취합하여 모델의 성능을 향상시킵니다.
사이킷런 모듈의 RandomForestClassifier 함수를 통해 모델을 생성할 수 있습니다. 하이퍼 파라미터에는 max_features, n_estimator, min_sample_splits 등이 있습니다.
max_features는 부트스트랩을 위한 특징 개수를 설정하며, 일반적으로 n차원의 데이터 세트의 경우 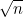 의 반올림값을 설정합니다. 의 반올림값을 설정합니다.
n_estimator는 트리의 개수를 설정하며, 트리의 개수가 많을수록 성능은 좋아지지만 시간이 오래 걸립니다. 일반적으로 100, 200, 500을 설정합니다.
min_sample_splits는 노드분할에 필요한 최소 샘플 개수를 설정합니다. 너무 작으면 과대적합, 너무 크면 과소적합이 될 수 있습니다. 일반적으로 10, 30, 50으로 설정합니다.
기존 데이터를 통해 랜덤 포레스트 모델을 훈련합니다. 트리 모델이 100배 증가했으므로 시간도 100배 증가합니다.. 조금 오래 걸립니다.
훈련이 끝나면 정확도와 혼동행렬을 확인해봅시다. 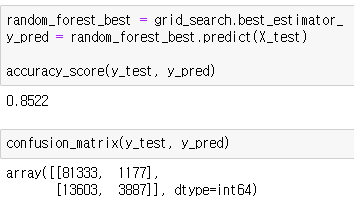
하나의 결정트리 모델에서는 정확도가 0.83249였는데 랜덤포레스트 모델의 경우 정확도가 0.8522로 성능이 더 좋아졌습니다.
ROC 커브를 비교해보세요.

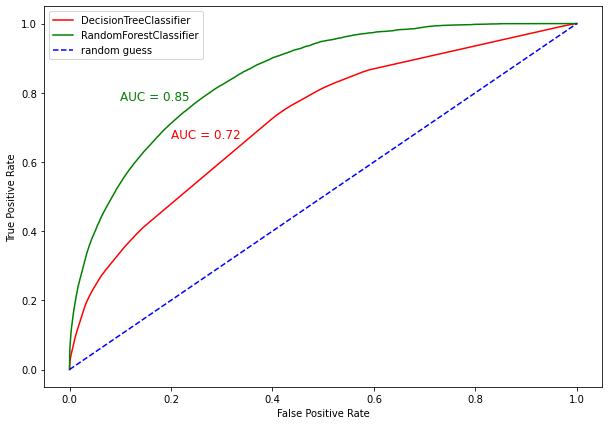
|  스팟
스팟