
1. 편향(bias)과 분산(variance)
편향(bias)이란 실제 값과 예측 값 간의 차이를 말하며, 분산(variance)란 예측값이 흩어진 정도를 말합니다.
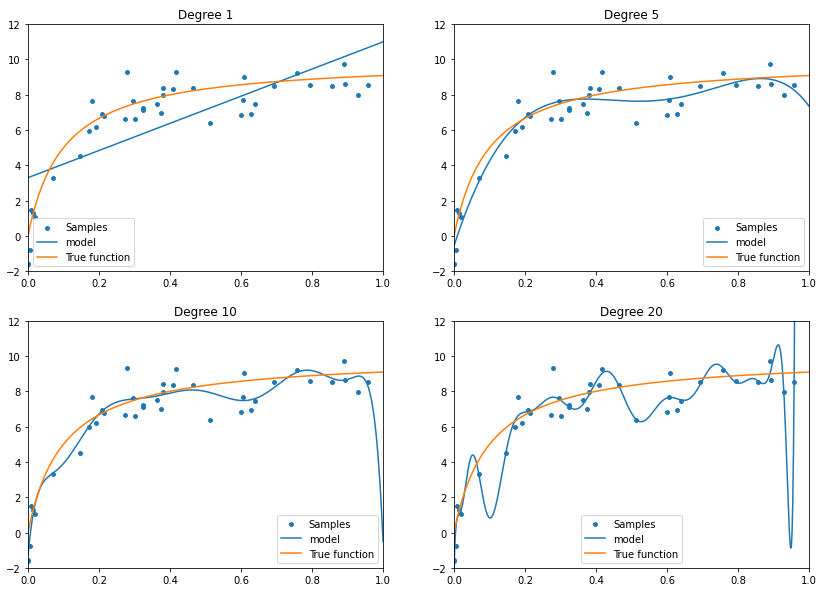
Degree 1 모델을 보면 샘플 데이터와 오차가 큰 것을 확인할 수 있습니다. 이런 현상을 과소적합(Underfitting)이라고 합니다. 고편향 모델은 구조가 너무 단순하여 과소적합이 발생하므로 이를 해결하기 위해서 모델의 복잡도를 증가시켜주면 됩니다. 선형회귀모델에서는 차수를 증가시켜주면 모델의 복잡도가 증가합니다.
반면 Degree 20 모델을 보면 샘플 데이터와 오차가 거의 없지만 실제 모델(True function)과는 차이가 납니다. 즉, 분산이 큽니다. 이런 현상을 과대적합(Overfitting)이라고 합니다. 고분산 모델은 구조가 너무 복잡하여 노이즈까지 훈련하여 발생합니다. 이를 해결하기 위해서는 모델의 복잡도를 감소시켜주면 됩니다.
편향과 분산은 트레이드오프(Trade Off) 관계에 있습니다. 즉, 편향을 감소시키기 위해 모델의 복잡도를 증가시키면 분산이 커지고, 분산을 감소시키기 위해 모델의 복잡도를 감소시키면 편향이 커집니다.
2. 검증곡선(Validation Curve)
편향과 분산 사이의 트레이드오프에서 가장 효율적인 지점을 찾기위해서는 검증곡선을 이용합니다. 검증곡선은 복잡도에 따른 정확도를 나타냅니다. 훈련 데이터와 검증 데이터의 정확도를 비교하여 가장 효율적인 복잡도를 찾아내면 됩니다.
지난번 글에서 검증 데이터를 설명하면서 작성한 것과 같이 반복문을 통해 복잡도에 따른 정확도를 측정해도 되지만 사이킷런의 validation_curve 함수를 사용할 수도 있습니다. 첫번째 매개변수로 모델객체를, 두번째 매개변수로 특징행렬을 , 세번째 매개변수로 대상벡터를, 매개변수 param_name에는 모델 파라미터 이름을, 매개변수 param_range에는 해당 파라미터 이름의 데이터를 넣어줍니다. 교차검증을 위해 파라미터 cv도 설정해줍시다.
주피터 노트북을 사용하여 아래 코드를 작성해보세요. 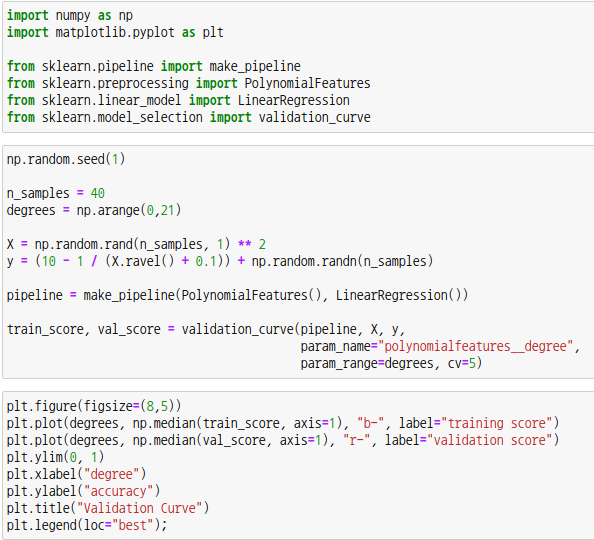
사이킷런의 PolynomialFeatures 함수는 선형회귀모델의 차수를 설정하는 전처리 도구입니다. 파이프라인은 연속된 변환을 순서대로 실행하도록 도와주는 도구입니다. make_pipeline 함수를 통해 선형회귀모델에 차수를 설정해줍시다. 매개변수로 전처리도구 PolynomialFeatures 객체와 선형회귀모델 객체를 넣어주면 됩니다.
validation_curve 함수를 통해 차수별로 정확도를 구할 수 있습니다. 모델 객체에는 생성한 파이프라인 객체를 넣어주고 훈련 데이터로 특징행렬 X와 대상벡터 y를 넣어줍니다. param_name에는 "polynomialfeatures__degree"를 입력합니다. param_range에는 차수의 범위를 입력하면 되는데 위에서는 넘피모듈의 arange 함수를 통해 0부터 20까지 범위를 생성하여 넣어주었습니다. 교차검증을 위해 cv는 5로 설정했습니다.
측정된 훈련 데이터 정확도와 검증 데이터 정확도를 matplotlib 모듈을 통해 시각화하면 다음과 같이 출력됩니다.
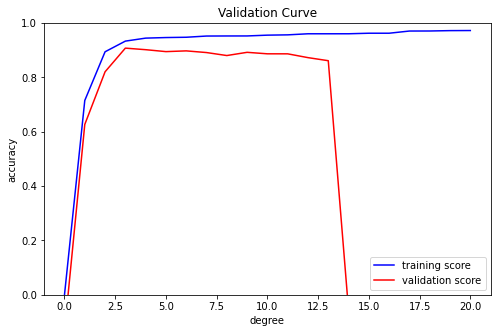
대략 차수가 3일때 제일 적합한 모델이 생성된다는 것을 확인할 수 있습니다.
3. 학습곡선(Learning Curve)
학습곡선은 데이터의 크기에 따른 정확도를 나타냅니다. 사이킷런 모듈의 learning_curve 함수를 통해 측정할 수 있습니다. 매개변수로 모델객체, 특징행렬, 대상벡터를 순서대로 받으며, cv를 설정하여 교차검증을 할 수 있고 train_sizes를 설정하여 데이터 사이즈를 특정 구간으로 나눌 수 있습니다.
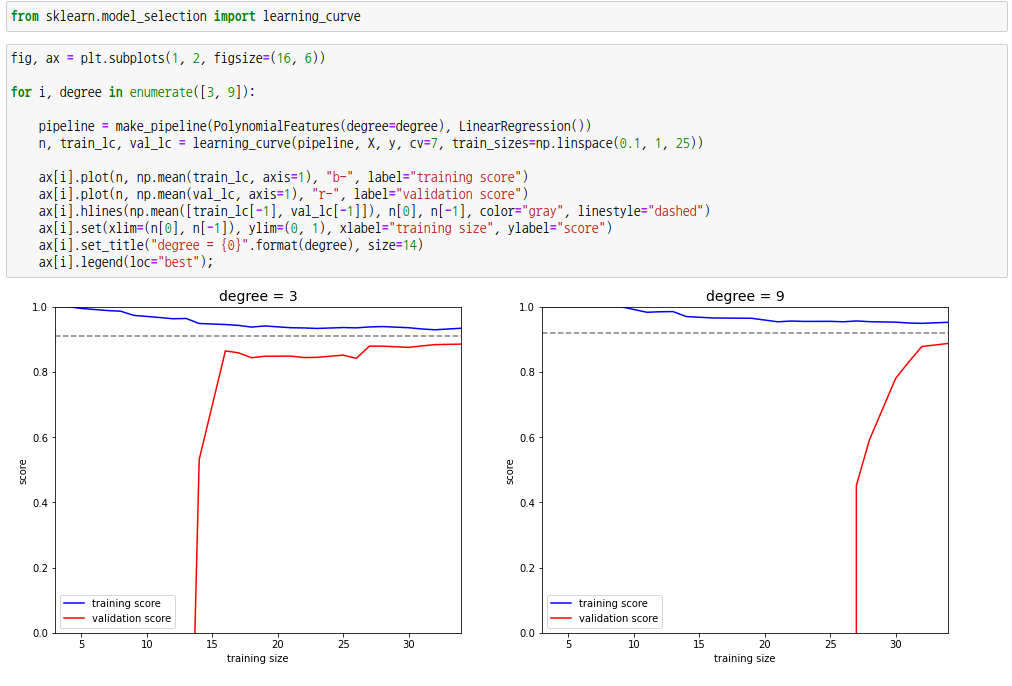
학습곡선을 통해 훈련 데이터의 크기가 커질수록 최적의 모델을 얻을 수 있다는 것을 확인할 수 있습니다. degree 3 모델에서는 15개 이상부터는 특정 값에 수렴하게 됩니다. 즉, 적절한 데이터의 크기는 15개 이상이며, 그 이후로는 데이터의 크기가 커져도 개선되지 않습니다. 이때 복잡도를 증가시킨다면 더 많은 데이터로부터 최적의 모델을 얻을 수 있습니다. 다만 위에 그림과 같이 분산은 증가하게 됩니다.
4. 그리드 서치(GridSearchCV)
그리드 서치는 검증 점수를 최대화하는 모델을 찾아내는 자동화 도구입니다. 사이킷런 모듈의 GridSearchCV 함수를 사용합니다. 매개변수는 모델 객체, 파라미터를 넣어줍니다. 교차검증을 위해 cv를 설정할 수도 있습니다.
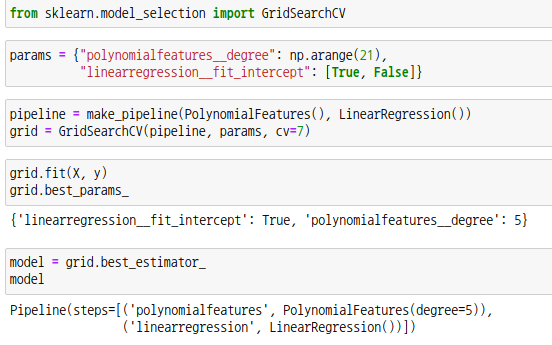
모델은 파이프라인을 통해 PolynomialFeatures 객체와 LinearRegression 객체를 연결했습니다. 파라미터로는 차수를 0 ~ 20까지 설정하고, fit_intercept를 True와 False로 설정했습니다. 총 21 * 2 = 41개의 모델이 생성되고 여기서 최적의 모델을 찾을 수 있습니다.
그리드 모델 객체의 fit 함수를 통해 특징행렬과 대상벡터를 넣어 훈련시키면 best_estimator_ 멤버를 통해 최적의 모델 객체를 얻을 수 있습니다. 그리드 객체의 best_params_ 멤버를 출력해보면 최적의 파라미터가 출력됩니다.
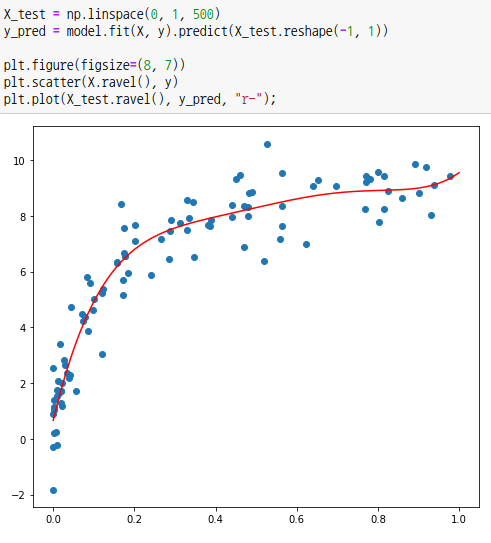
해당 모델을 통해 테스트 데이터로 훈련시키고 테스트 데이터로 평가를 합니다.
|  스팟
스팟