
1. 훈련(training) 데이터와 테스트(test) 데이터
머신러닝 모델의 목표는 기존의 데이터가 얼마나 정확한지 추측하는 것이 아니라 새로운 데이터로 부터 결과가 얼마나 정확한지를 예상하는 것입니다. 이것이 머신러닝과 통계학의 차이점이라 볼 수 있습니다.
모델을 평가할때 훈련에 사용한 데이터를 사용하여 평가하면 어떻게 될까요? 쉽게 생각해봅시다. 훈련된 모델은 기출문제에 대한 정답을 이미 외우고 있습니다. 그러므로 기출문제가 나온다면 정답률은 100%에 가까울 것입니다.
예를 들어보겠습니다.
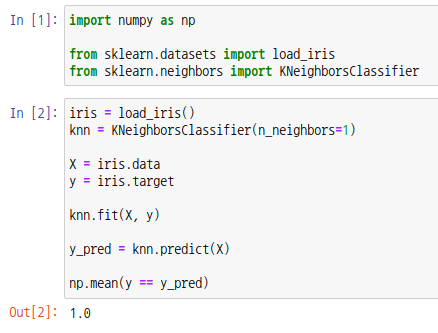
KNN 이라는 알고리즘을 사용하는 분류 모델을 통해 iris 데이터를 훈련시키고, 훈련에 사용한 데이터를 통해 결과값을 예측해보았습니다. 실제값과 예측값을 비교하면 정확도가 1이 나오는 것을 확인할 수 있습니다. 즉, 실제값과 예측값이 모두 동일합니다. 그렇다고 해서 이 모델이 iris의 종을 구분할 수 있는 완벽한 모델이라고 할 수 없습니다. 훈련 데이터에 포함되지 않은 새로운 데이터를 입력하면 실제값과 예측값이 달라질 수도 있습니다.
이런 이유로 모델을 평가할 때는 훈련에 사용한 데이터와 다른 데이터를 사용합니다. 훈련에 사용하는 데이터를 훈련(training) 데이터, 평가에 사용하는 데이터를 테스트(test) 데이터라고 합니다.
보통 전체 데이터셋을 4:1 또는 3:2 비율로 나눠 사용합니다. 사이킷런 모듈의 train_test_split 함수를 통해 데이터셋을 분리할 수 있습니다. 매개변수로 특징행렬, 대상벡터를 넣어주고, test_size 에는 테스트 데이터의 비율을, random_state 에는 랜덤 시드값을 넣어줍니다.
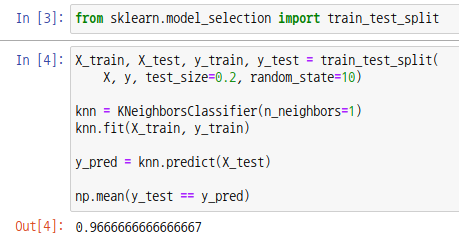
모델을 훈련할때는 훈련 데이터를, 평가할때는 테스트 데이터를 사용합니다.
위에처럼 넘피 모듈을 통해 정확도를 구할 수도 있지만 KNN 모델 객체는 score 함수를 통해 정확도를 구할 수도 있습니다. 매개변수로 테스트 데이터에 대한 특징행렬과 대상벡터를 넣어줍니다. 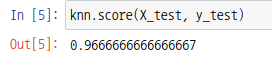
사이킷런 모듈의 accuracy_score 함수를 통해서도 가능합니다. 매개변수로 실제값과 예측값을 넣어줍니다. 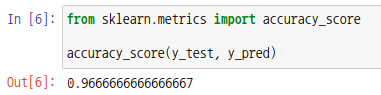
2. 검증(validation) 데이터
머신러닝 모델은 하이퍼파라미터를 설정할 수 있습니다. 하이퍼파라미터에 따라 모델의 성능은 달라집니다. 그러므로 각각의 모델을 평가하기 위한 데이터가 필요한데 이를 검증(validation) 데이터라고 합니다.
검증 데이터와 테스트 데이터는 따로 분리하여 사용하는데 여기서는 위에서 나눠둔 테스트 데이터를 검증 데이터로 사용하여 k값에 따른 KNN모델의 정확도를 확인해보겠습니다.
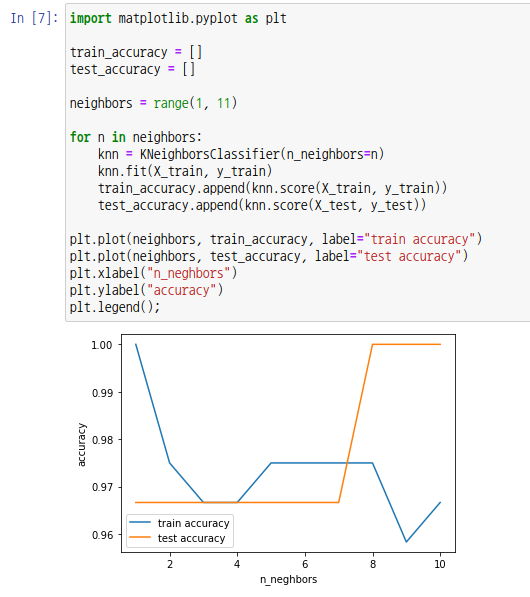
matplotlib 모듈을 통해 k값(하이퍼파라미터 n_neghbors)에 따른 훈련 데이터와 검증 데이터를 시각화했습니다. 대략 k값이 8일때 테스트 데이터와 훈련 데이터의 정확도가 가장 높음을 확인할 수 있습니다.
3. 교차검증(Cross Validation)
교차검증은 모델을 평가하는 방법 중 하나입니다. 기본적으로 훈련 데이터를 기반으로 모델링을 하고 테스트 데이터로 해당 모델의 성능을 평가합니다. 고정된 테스트 데이터를 통해 모델을 평가하고 수정하는 과정을 반복한다면 이 모델은 테스트 데이터에 대하여 과대적합(overfitting)이 일어나게 됩니다. 즉, 테스트 데이터에 대해서는 정확하지만 다른 새로운 데이터에 대해서는 예측값이 실제값과 달라질 수 있습니다.
이를 해결하기 위한 방법이 교차검증입니다. 교차검증은 훈련 데이터를 훈련 데이터와 검증 데이터로 나누어 검증 데이터를 통해 모델을 검증합니다.
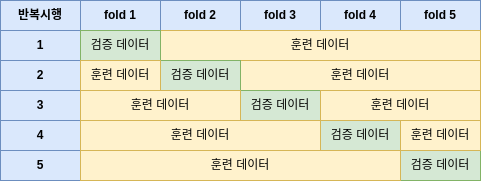
교차검증이라고 하면 보통 k겹 교차검증(K-Fold Cross Validation)을 말합니다. k겹 교차검증은 데이터를 무작위로 k개의 폴드로 나누고, 각 시행단계마다 특정 폴드를 검증 데이터로, 나머지를 훈련 데이터로 사용하여 각 모델을 검증합니다. 총 k번의 반복시행이 일어나고, 최종적으로는 각 검증값에 대한 평균을 계산하여 모델 성능을 평가합니다.
사이킷런 모듈에서는 cross_val_score 함수를 통해 k겹 교차검증이 가능합니다. 첫번째 매개변수로 모델객체를, 두번째 매개변수로 특징행렬을, 세번째 매개변수로 대상벡터를, 매개변수 cv에는 반복횟수(k값)을 넣습니다. 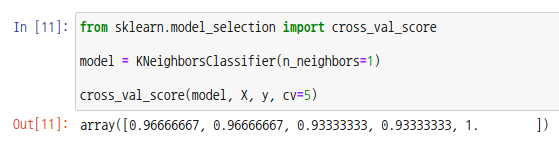
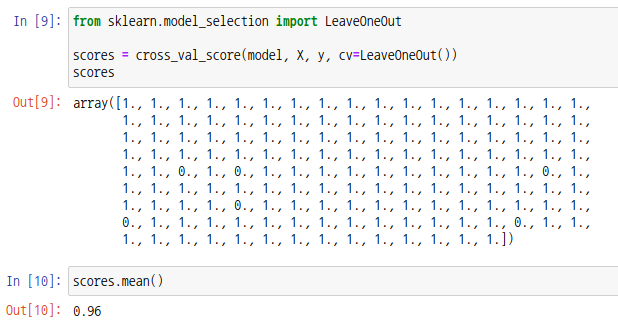
또다른 교차검증으로는 LOOCV(Leave-one-out Cross Validation)가 있습니다. LOOCV는 일종의 k겹 교차검증으로, n개의 데이터셋에서 1개를 검증 데이터로, 나머지 n-1개를 훈련 데이터로 사용하여 모델을 검증합니다. 총 n번의 반복시행이 발생합니다.
사아킷런 모듈에서는 LeaveOneOut 객체를 cross_val_score 함수의 cv 매개변수에 넣어주면 LOOCV가 가능합니다.
|  스팟
스팟