
Scikit-Leanrn 라이브러리는 머신러닝 알고리즘을 구현한 오픈소스 라이브러리입니다. 알고리즘은 파이썬 클래스로 구현되어 있으며, 데이터셋은 Numpy 배열, Pandas DataFrame, SciPy 희소행렬을 사용할 수 있습니다.
이번 글에서는 사이킷런을 통해 머신러닝 모델을 생성하면서 그 절차를 알아보겠습니다.
1. 데이터 표현 방식
지도학습을 기준으로 머신러닝에 필요한 데이터는 입력에 해당하는 특징행렬(Feature Matrix)과 출력에 해당하는 대상벡터(Target Vector) 입니다.
특징행렬은 행(row)을 나타내는 표본(sample)과 열(column)을 나타내는 특징(feature)으로 구성됩니다. 2차원 배열 구조를 사용하며, 관례적으로 변수 X에 저장합니다.
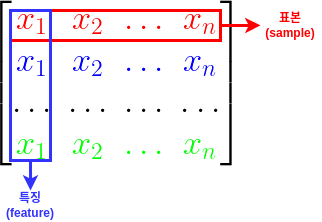
표본은 데이터셋이 설명하는 개별 객체를 나타내며, 특징은 각 객체에 대한 개별 관측치를 나타냅니다. 즉, 각 특징이 모여 하나의 표본을 구성합니다.
대상벡터는 레이블(label)이라 부르는 각 표본에 대한 결과값을 나타냅니다. 1차원 배열구조를 사용하며, 데이터 길이는 표본의 개수와 같습니다.
2. 추정기(Estimator) 만들기
사이킷런 모듈을 통해 추정기를 만들어 보겠습니다. 추정기는 쉽게 말해서 학습을 통해 만들어진 알고리즘 입니다. 이 알고리즘을 통해 결과값을 예측가능합니다.
1) 데이터 준비
우선 추정기를 만들기 위한 데이터가 필요합니다. 임의로 데이터를 생성하겠습니다.
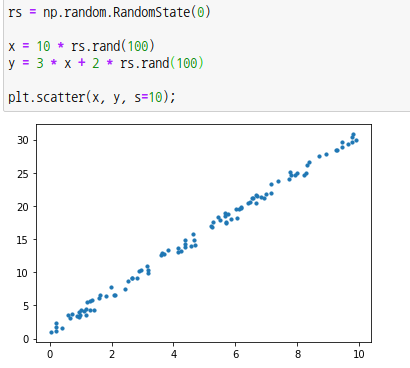
넘피모듈의 랜덤함수를 통해 x값과 y값을 임의로 100개 생성합니다. matplotlib 모듈을 통해 산점도를 그려보면 위의 그림과 같이 직선 형태로 산점도가 생성됩니다.
여기서 자세히 설명하지 않겠지만 해당 산점도는 높은 정상관이며, x값과 y값이 상관관계가 있음을 나타냅니다.
2) 모델 클래스 선택
이전 글에서 짧게 설명했는데 연속형 수치데이터를 예측하기 위해서는 회귀모델을 사용합니다. y에 대한 독립변수는 x 하나이므로 선형회귀모델을 사용합니다.
3) 모델 인스턴스 생성과 하이퍼파라미터 선택
선형회귀모델은 사이킷런 모듈의 LinearRegression 함수를 통해 생성할 수 있습니다. 하이퍼파라미터는 모델을 설정하는 매개변수입니다.

4) 특징행렬과 대상벡터 준비
x값을 특징으로 하는 특징행렬과 대상벡터인 결과값 y를 준비합니다. x는 1차원 배열이므로 reshape 함수를 통해 2차원 배열로 변경해줍시다. 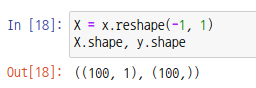
5) 모델을 데이터에 적합
모델의 fit 함수를 통해 데이터를 적합시킵니다. 하이퍼파라미터로 특징행렬 X와 대상벡터 y를 넣어줍니다. 이 과정을 통해 선형회귀모델은 추정회귀방정식 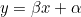 에서 회귀계수 에서 회귀계수 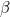 와 절편 와 절편 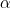 를 결정합니다. 를 결정합니다. 이런 과정을 훈련(training)이라고 합니다.
적합시킨 후 모델의 coef_ 멤버를 통해 회귀계수를, intercept_ 멤버를 통해 절편을 확인할 수 있습니다.

6) 새로운 데이터를 통한 예측
훈련된 모델은 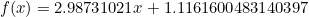 라는 추정회귀방정식을 가집니다. 라는 추정회귀방정식을 가집니다.
이제 새로운 x값을 통해 y값의 예측이 가능합니다.
y값의 예측은 모델의 predict 함수를 사용합니다. 하이퍼파라미터로 새로운 특징행렬을 넣어줍니다.
새로운 데이터 x_new는 numpy 모듈의 linspace 함수를 통해 -1과 11 사이를 100개로 나눈 값을 입력합니다. 새로운 데이터에 대한 예측값은 y_pred 함수에 넣어줍니다.
새로운 데이터 x_new와 예측값 y_pred을 이용하여 선형플롯을 만들어 봅시다.
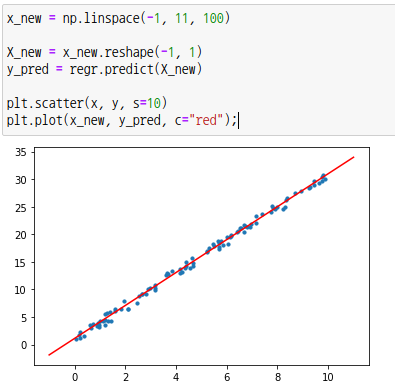
7) 모델평가
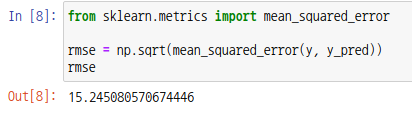
예측선을 보면 실제 결과값 y와 조금씩 차이가 납니다. 예측값과 실제값의 차이를 잔차 또는 오차라고 합니다. 오차의 표준값을 구해야 하는데 이때 평균 제곱근 오차(RMSE, Root Mean Squared Error)를 사용합니다. 사이킷런에는 평균 제곱 오차(MSE, Mean Squared Error)를 구하는 함수 mean_squared_error가 있습니다. 해당 함수를 통해 RMSE를 구할 수 있습니다. RMSE가 0에 가까울수록 적합한 모델이 됩니다.
|  스팟
스팟